ChatClient Integration¶
SessionMemoryAdvisor is the primary integration point between Spring AI Session and a
ChatClient. It wires session management into the ChatClient pipeline transparently —
no manual history loading or appending required in application code.
What the advisor does¶
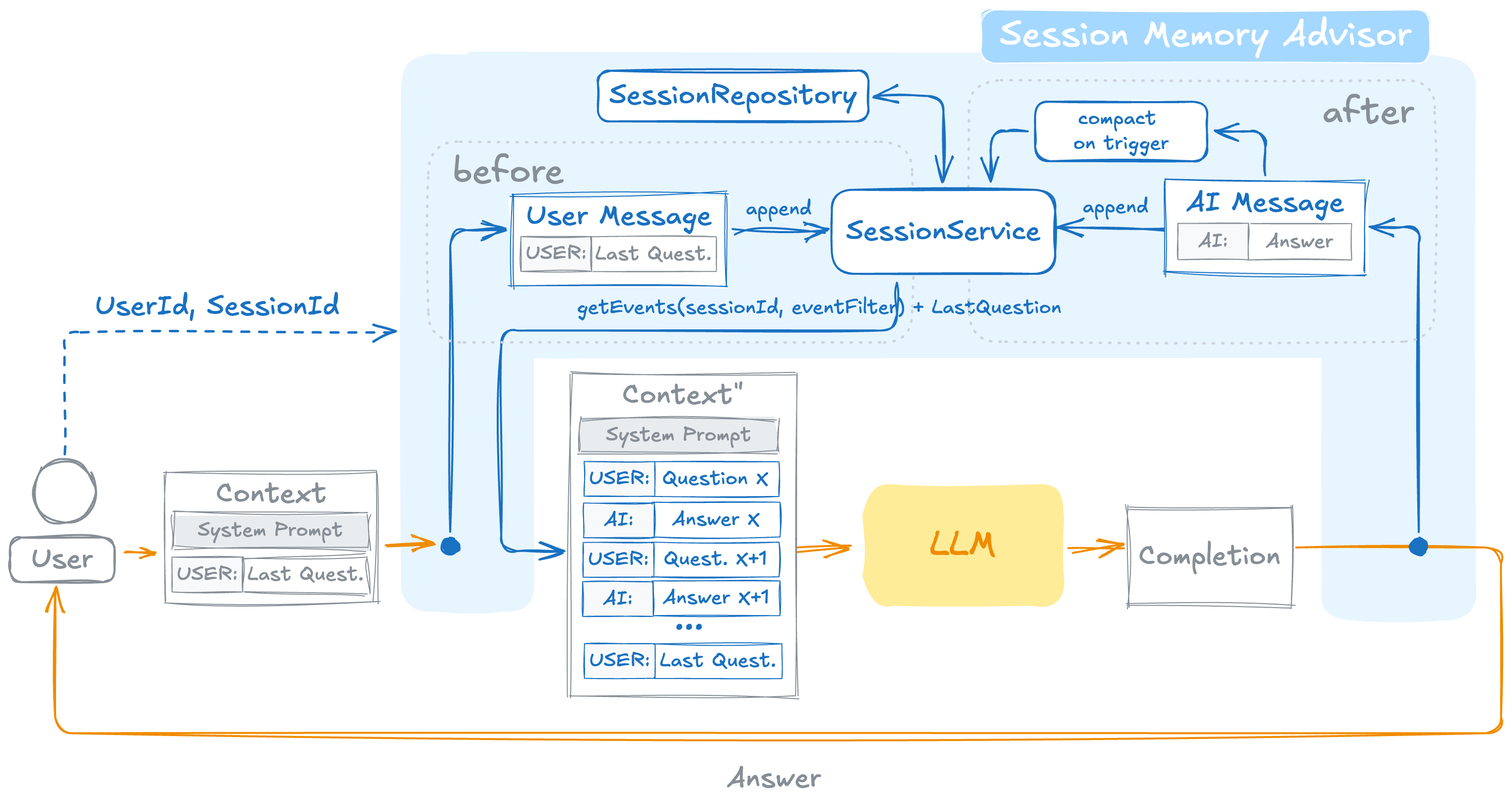
On every request the advisor:
- Resolves the session ID from
SESSION_ID_CONTEXT_KEYin the advisor context — this key must be present on every request. If the session does not exist, it is created automatically using theUSER_ID_CONTEXT_KEYvalue (ordefaultUserId) and the resolved session ID. If the session already exists andUSER_ID_CONTEXT_KEYis set, the advisor validates that the requesting user owns the session and throwsIllegalStateExceptionon mismatch. - Retrieves the session's event history (filtered by the configured
eventFilter, defaultEventFilter.all()) and prepends it to the prompt messages. If the request context contains anEVENT_FILTER_CONTEXT_KEYvalue, it is merged with the advisor-level filter — request-level fields win over advisor defaults.EventFilter.active()is then unconditionally merged in on top, so archived (compacted-out) events never reach the prompt regardless of what the configured or per-request filter allows. - Reorders all
SystemMessageinstances to the front of the combined message list, preserving their relative order. - Appends the current user message to the session, if the configured
MessageFilteraccepts it. - After the model responds, appends the assistant message(s) through the configured
MessageFilter(default:MessageFilter.skipEmptyMessages()). By default, empty assistant messages (blank text, no tool calls, and no media) are skipped — some models (e.g. Bedrock Converse) emit an emptyend_turnframe after tool use that would otherwise be replayed and rejected on the next request. - If a trigger fires, runs compaction synchronously before returning — the full turn (user + assistant) is already written at this point, so there is no race between compaction and message appending.
The diagram below shows the round-trip: the before phase loads history and builds the expanded prompt, the after phase appends the assistant message and compacts on trigger.
Setup¶
SessionMemoryAdvisor advisor = SessionMemoryAdvisor.builder(sessionService)
.defaultUserId("alice")
// Compact when 20 turns accumulate, using LLM summarization to retain context
.compactionTrigger(new TurnCountTrigger(20))
.compactionStrategy(
RecursiveSummarizationCompactionStrategy.builder(chatClient)
.maxEventsToKeep(10)
.build()
)
.build();
ChatClient client = ChatClient.builder(chatModel)
.defaultAdvisors(advisor)
.build();
Session ID is required on every request
SESSION_ID_CONTEXT_KEY must be set in the advisor context on every call.
Omitting it throws IllegalStateException. This is intentional — a shared fallback
session ID would silently merge history across different users.
Trigger and strategy must be set together
Setting only one of compactionTrigger or compactionStrategy throws
IllegalStateException. Set both or neither.
Default advisor order
The default order is Ordered.HIGHEST_PRECEDENCE + 1000 (≈ Integer.MIN_VALUE + 1000),
giving SessionMemoryAdvisor higher precedence than ToolAdvisor (order 300).
Higher precedence means before() runs first and after() runs last, so
SessionMemoryAdvisor wraps the tool advisor — tool results are fully resolved before
the session write in after(). Override with .order(n) if your pipeline requires a
different position.
Passing a session ID per request¶
Pass a session ID at call time via the advisor context:
String response = client.prompt()
.user("Hello!")
.advisors(a -> a.param(SessionMemoryAdvisor.SESSION_ID_CONTEXT_KEY, "session-abc"))
.call()
.content();
If no session exists for the given ID, the advisor creates one automatically using the
USER_ID_CONTEXT_KEY value from the request context, falling back to defaultUserId.
Ownership enforcement
When USER_ID_CONTEXT_KEY is present and the session already exists, the advisor
checks that the supplied user ID matches session.userId(). A mismatch throws
IllegalStateException — this prevents one user from reading or appending to
another user's session if session IDs are ever guessable or shared.
The check is skipped when USER_ID_CONTEXT_KEY is absent so that callers
which rely solely on defaultUserId (or do their own authorization upstream) are
not affected.
Context keys¶
| Key constant | String value | Purpose |
|---|---|---|
SESSION_ID_CONTEXT_KEY |
"chat_memory_conversation_id" (= ChatMemory.CONVERSATION_ID) |
Routes the request to a session |
USER_ID_CONTEXT_KEY |
"chat_memory_user_id" |
Used when auto-creating a session; also enforces ownership on existing sessions when set |
EVENT_FILTER_CONTEXT_KEY |
"chat_memory_event_filter_id" |
Per-request EventFilter merged with the advisor-level filter |
Per-request filter override¶
Pass an EventFilter via EVENT_FILTER_CONTEXT_KEY to narrow or adjust history
retrieval on a single call without reconfiguring the advisor:
// Advisor is configured with EventFilter.all() (default).
// This request overrides to see only the last 5 events.
String response = client.prompt()
.user("Quick summary please")
.advisors(a -> a
.param(SessionMemoryAdvisor.SESSION_ID_CONTEXT_KEY, sessionId)
.param(SessionMemoryAdvisor.EVENT_FILTER_CONTEXT_KEY, EventFilter.lastN(5))
)
.call()
.content();
EventFilter.merge() semantics: every non-null field from the request filter replaces
the corresponding field from the advisor default; the two boolean flags, excludeSynthetic
and excludeArchived, are OR-ed so either side can opt in. A null value for
EVENT_FILTER_CONTEXT_KEY is ignored.
Filtering what gets persisted (MessageFilter)¶
While EventFilter controls which stored events are loaded into the next prompt,
MessageFilter controls which messages get stored at all. A message rejected by the
filter is never persisted and therefore never replayed on later requests. The outgoing
prompt is unaffected — filtering applies to persistence only.
EventFilter (read side) |
MessageFilter (write side) |
|
|---|---|---|
| Applies when | Loading history in before() |
Appending messages in before() / after() |
| Operates on | Stored SessionEvents |
Messages about to be persisted |
| Rejected items | Stay in storage, hidden from the prompt | Never written to storage |
Configure it on the builder:
SessionMemoryAdvisor advisor = SessionMemoryAdvisor.builder(sessionService)
// Persist only user and assistant messages (e.g. keep verbose tool
// responses out of the session log), still skipping empty frames.
.messageFilter(
MessageFilter.byMessageType(MessageType.USER, MessageType.ASSISTANT)
.and(MessageFilter.skipEmptyMessages())
)
.build();
Built-in factories:
| Factory | Behavior |
|---|---|
MessageFilter.all() |
Persists every message (no filtering) |
MessageFilter.skipEmptyMessages() |
Skips assistant messages with blank/null text, no tool calls, and no media (the default) |
MessageFilter.byMessageType(types...) |
Persists only the listed MessageTypes |
MessageFilter.containsText(keyword) |
Persists only messages whose text contains the keyword (case-insensitive) |
MessageFilter is a @FunctionalInterface, so a lambda works too, and filters compose
via and(), or(), and negate():
// Never persist messages containing "confidential"
.messageFilter(
MessageFilter.containsText("confidential").negate()
.and(MessageFilter.skipEmptyMessages())
)
Compose, don't replace
Setting a custom messageFilter replaces the default
skipEmptyMessages() protection. If you still want empty assistant frames
filtered out (recommended — some models reject them when replayed as history),
compose your filter with it via .and(MessageFilter.skipEmptyMessages()).
Concurrent compaction safety¶
If two requests for the same session complete concurrently (e.g. parallel fan-out), both
after() calls may reach the compaction step simultaneously. Compaction uses an optimistic
compare-and-swap write via SessionRepository.compactEvents(sessionId, archivedEvents,
retainedEvents, expectedVersion). The event-log version is read before events are fetched;
if another writer mutates the log between that read and the CAS write, compactEvents
returns false and the second writer skips silently — no compacted result is lost or
corrupted.
Scheduler pinning¶
Both the blocking (advise()) and streaming (adviseStream()) paths run before() and
after() on the configured Scheduler (default: BaseAdvisor.DEFAULT_SCHEDULER). In
adviseStream(), a second .publishOn(scheduler) is applied after
.flatMapMany(chain::nextStream) so that the aggregation callback and compaction always
run on the scheduler rather than the LLM streaming thread.